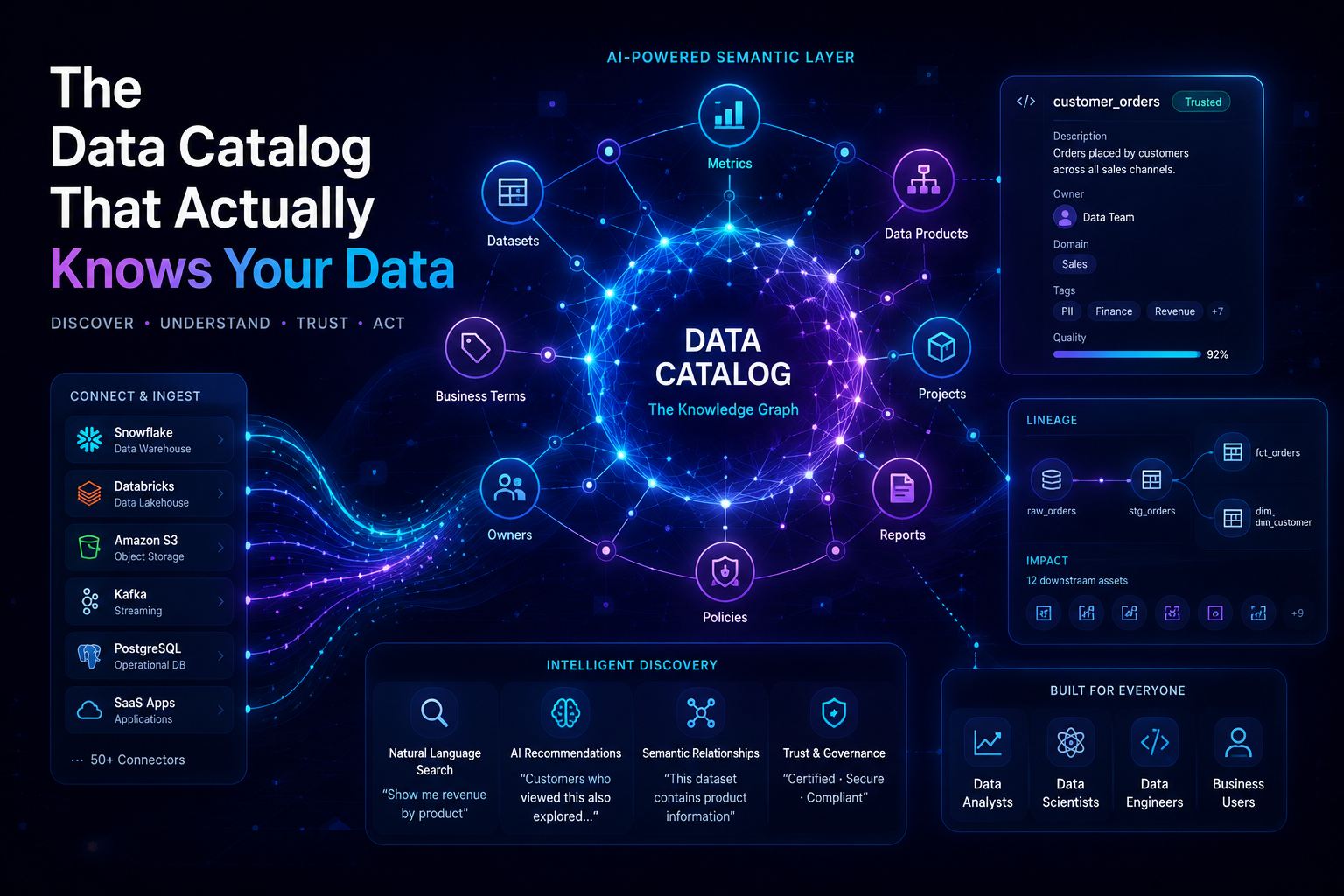
Every data team eventually hits the same wall. Someone asks where a number came from. Someone else wants to change a column. A third person submits a GDPR deletion request. And the answer to all three questions is the same uncomfortable shrug: we're not really sure.
The data catalog is the system that eliminates that shrug. Not the governance checkbox variety that lives in a wiki and goes stale by Tuesday — but an active, event-driven, graph-backed system that tracks what your data is, who owns it, where it came from, how fresh it is, and who is allowed to touch it.
This post walks through how to design that system from first principles, across a heterogeneous stack of warehouses, object stores, streaming systems, and transformation frameworks.
Data without lineage is like a financial audit without receipts. You can trust the number or you can verify it. You cannot do both.
Why the Problem Is Hard
The difficulty is not storing metadata. That part is easy. The difficulty is that your data lives in a dozen different systems — Snowflake, S3, Postgres, Kafka, dbt, Spark — each with its own notion of a "table," its own permission model, its own schema format, and its own idea of what "freshness" means.
A catalog that understands only one of those systems is just a fancy README. A catalog that understands all of them, in a unified model, is genuine infrastructure. The design challenge is building the latter without creating an unmaintainable sprawl of custom connectors and hand-rolled scrapers.
A data catalog is a metadata management system that provides a unified, searchable inventory of data assets across an organization — including their structure, ownership, provenance, quality, and access controls.
The Architecture in Five Layers
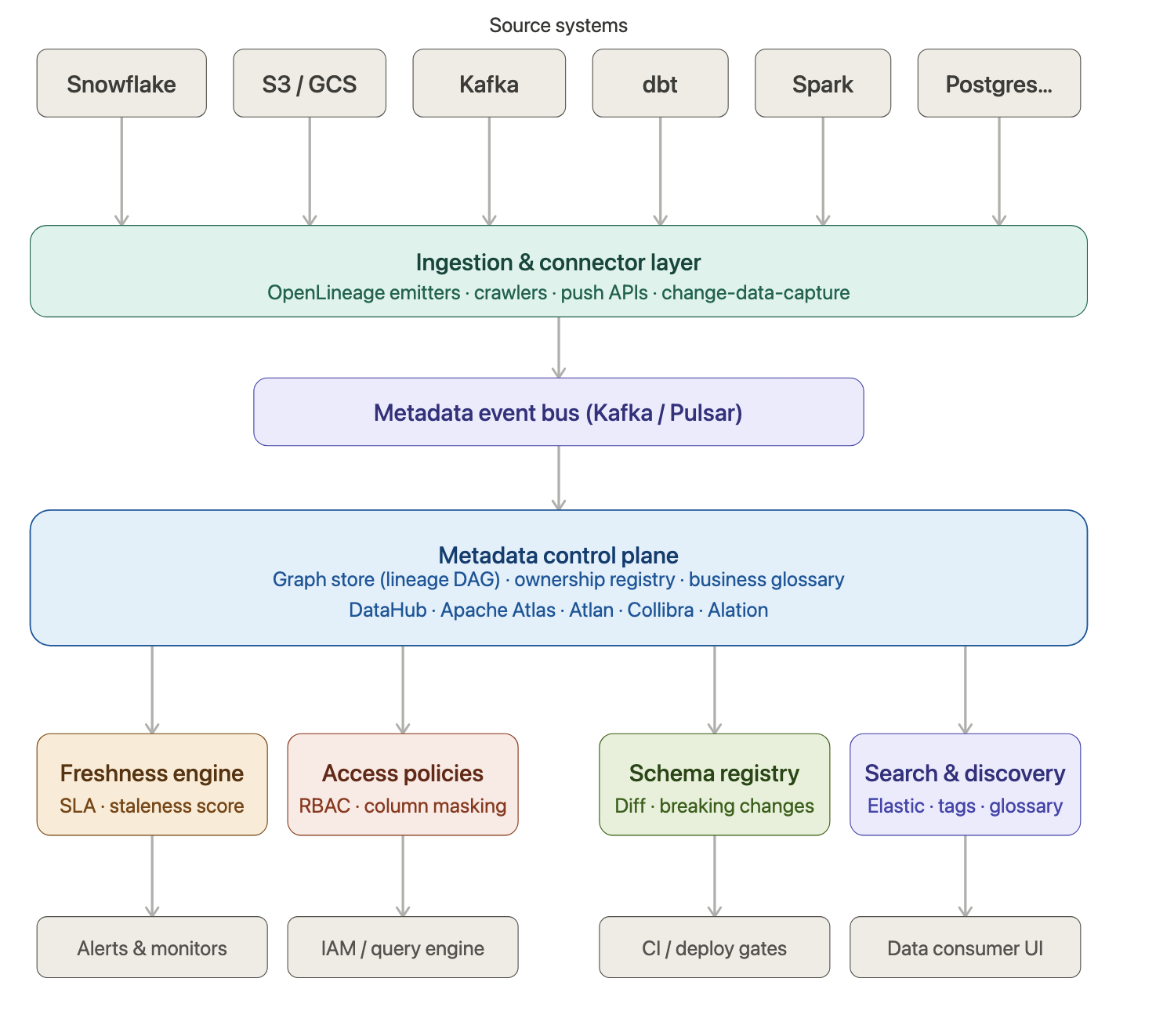
The right architecture separates concerns cleanly. Think of it as five layers, each with a distinct job, connected by an event-driven backbone.
-
Ingestion & Connectors Crawlers and push-based emitters that harvest metadata from every source system. OpenLineage for pipelines; schema crawlers for warehouses and lakes.
-
Metadata Event Bus All metadata mutations flow as immutable events through Kafka. This gives you an audit trail, replay capability, and decoupling from source systems.
-
Control Plane (Graph Store) A graph database models datasets, pipelines, users, and their relationships. Lineage traversal is , not .
-
Specialized Engines Separate subsystems handle freshness scoring, access policy evaluation, schema change detection, and full-text search — each optimized for its task.
-
Consumers & Enforcement Points The catalog is the source of truth, but enforcement happens at the query layer — Trino, Snowflake column security, S3 bucket policies, CI deploy gates.
Lineage: The Biography of Your Data
Lineage is the graph that records where data came from, what happened to it, and where it ended up. Every node is a dataset or a job. Every edge is a "produces" or "consumes" relationship, stamped with a timestamp and the transformation logic that created it.
The catalog stores these edges as a directed acyclic graph (DAG). A typical path through that graph looks like this:
Example lineage path — revenue dashboard
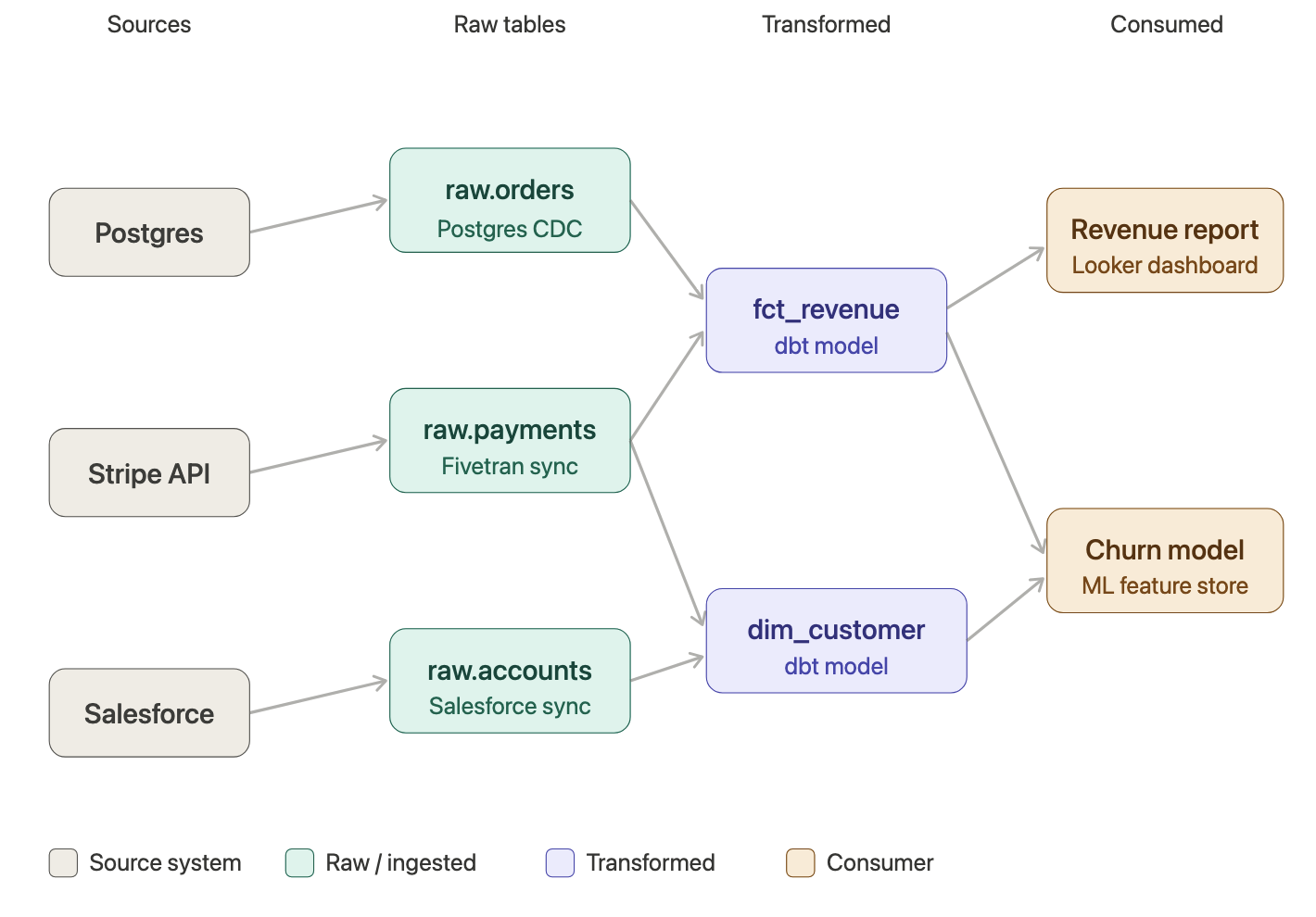
With this graph, two questions become trivially answerable. Root cause: the revenue number looks wrong — trace backward from the dashboard to find which upstream source introduced the error. Impact analysis: the DBA wants to rename a column in raw.orders — traverse forward to find every model, dashboard, and ML feature that depends on it before approving the migration.
Column-level lineage takes this further. Rather than knowing that fct_revenue depends on raw.orders, you know that the revenue_usd column specifically derives from amount_cents / 100 in raw.orders.amount_cents, joined with raw.payments.currency_code. This is the resolution you need for genuine compliance audits.
Lineage is captured by OpenLineage emitters embedded in dbt, Spark, and Airflow, which fire events on every job run. Those events are consumed from Kafka and written as edges into the graph store.
Freshness: More Than a Timestamp
Freshness sounds simple — when did this table last update? — but the naive implementation fails in two important ways. First, different datasets have radically different update cadences, so a single "stale after N hours" rule is useless. Second, a job can run successfully and write zero rows. That is a silent failure that a timestamp check will never catch.
The right model tracks three signals per dataset: last_seen (when did new rows arrive?), last_processed (when did the producing job last succeed?), and row_count_delta (how many rows did the last run write?). These flow into a time-series store — Prometheus or InfluxDB — and are evaluated by a freshness scorer.
The scorer computes a normalized value using exponential decay:
Freshness score formula # lag = how many minutes overdue the dataset is # expected_interval = the agreed update cadence in minutes score = e ^ ( -lag / expected_interval ) # On time → score = 1.0 # 1× interval late → score ≈ 0.37 # 2× interval late → score ≈ 0.14 # Severely late → score → 0.0
Because the score is normalized, you can compare freshness across datasets with completely different schedules — a CDC table and a monthly aggregation roll-up — using the same dashboard and the same alerting thresholds.
SLA thresholds are set per dataset by the owner. A real-time table feeding executive dashboards might warn below . A weekly batch table might only warn below . When a score breaches a threshold, the catalog pages the on-call engineer via PagerDuty and — optionally — blocks downstream jobs from consuming stale data.
Access Policies: Declare Once, Enforce Everywhere
The catalog stores access policies as metadata: who can read which datasets, which columns are masked for which roles, which datasets require data steward approval before access is granted. But — and this is the critical design choice — the catalog is the source of truth, not the enforcement point.
Enforcement happens at the query layer. A policy in the catalog that says "only the finance team can see orders.credit_card_last4" translates into a Snowflake column masking policy, a Trino column-level security rule, and an S3 bucket policy — applied at the system that actually serves the data. The catalog propagates those policies outward; it does not sit in the query path.
This separation matters enormously for performance and reliability. Your catalog can go down for maintenance without taking query access with it, because the policies are already materialized at the enforcement points.
Schema Changes: Breaking vs. Non-Breaking
Schema drift is how silent failures become production incidents. A column gets renamed. A type changes from VARCHAR to INT. A required field is dropped. None of these events throw an error at write time — they throw errors hours later, deep in a downstream transformation, when the damage has already propagated.
The schema registry in a well-designed catalog compares every new schema version against the previous one and classifies each change:
Schema change classification SAFE (non-breaking) ├── Adding a new nullable column ├── Adding a new table └── Widening a numeric type (INT → BIGINT) BREAKING ├── Dropping a column ├── Renaming a column ├── Narrowing a type (BIGINT → INT) └── Changing nullable → NOT NULL on existing column
Breaking changes can be blocked at the CI/CD layer. A deploy that introduces a breaking schema change fails its pull request check until the dataset owner and affected downstream owners have explicitly acknowledged the migration plan. This turns a class of silent production failures into a deliberate, reviewable process.
Tooling: Build vs. Buy
You do not need to build this from scratch. The open-source ecosystem has matured substantially.
| Tool | Type | Best for | Strengths |
|---|---|---|---|
| DataHub | OSS | Self-hosted, full control | Mature Kafka-backed ingestion, strong lineage, active community |
| Apache Atlas | OSS | Hadoop/HBase-heavy shops | Deep Ranger integration, tag-based governance |
| Marquez | OSS | Pure lineage tracking | OpenLineage-native, lightweight, simple API |
| Atlan | SaaS | Teams that want fast time-to-value | Excellent UX, deep dbt + BI integrations |
| Collibra | SaaS | Enterprise governance & compliance | Policy workflows, regulatory reporting, stewardship |
| Monte Carlo | SaaS | Data observability focus | Best-in-class freshness + volume + anomaly detection |
For most teams starting from scratch, DataHub is the strongest open-source choice — it covers lineage, ownership, freshness, and search with a polished React UI and a Kafka-backed ingestion model that scales cleanly. Pair it with dbt tests or Great Expectations for data quality signals, and Monte Carlo or Bigeye if you need deeper observability.
The graph store is the architectural heart. Lineage is inherently a DAG, and you need efficient traversal — not a join-heavy relational schema that collapses under ten hops of dependency.
The One Rule That Holds Everything Together
Every dataset in the catalog must have an owner. Not a team. Not a department. A named human with a pager. That owner is responsible for the SLA, the access policy, and the migration plan for any breaking schema change.
Without ownership, a data catalog is an archaeology project — a record of what the data used to be, maintained by nobody, trusted by nobody. With ownership, it becomes a living contract between the producers and consumers of data. The technology described in this post is sophisticated, but it serves a simple social purpose: making it impossible to claim you did not know.
Where to Start
If your organization has never run a data catalog, do not try to instrument everything at once. Start with your three most business-critical datasets — the ones that feed the dashboards your executives look at on Monday morning. Stand up DataHub or Marquez, wire up your dbt project (it already emits lineage), and register those three datasets with owners and SLAs.
Within a month you will have answered your first impact analysis question using the graph — "what breaks if I change this column?" — and that moment will sell the rest of the organization on the investment better than any architecture diagram could.
The data catalog is not a governance tax. It is the infrastructure that lets your data team move fast without leaving a trail of silent failures behind them.