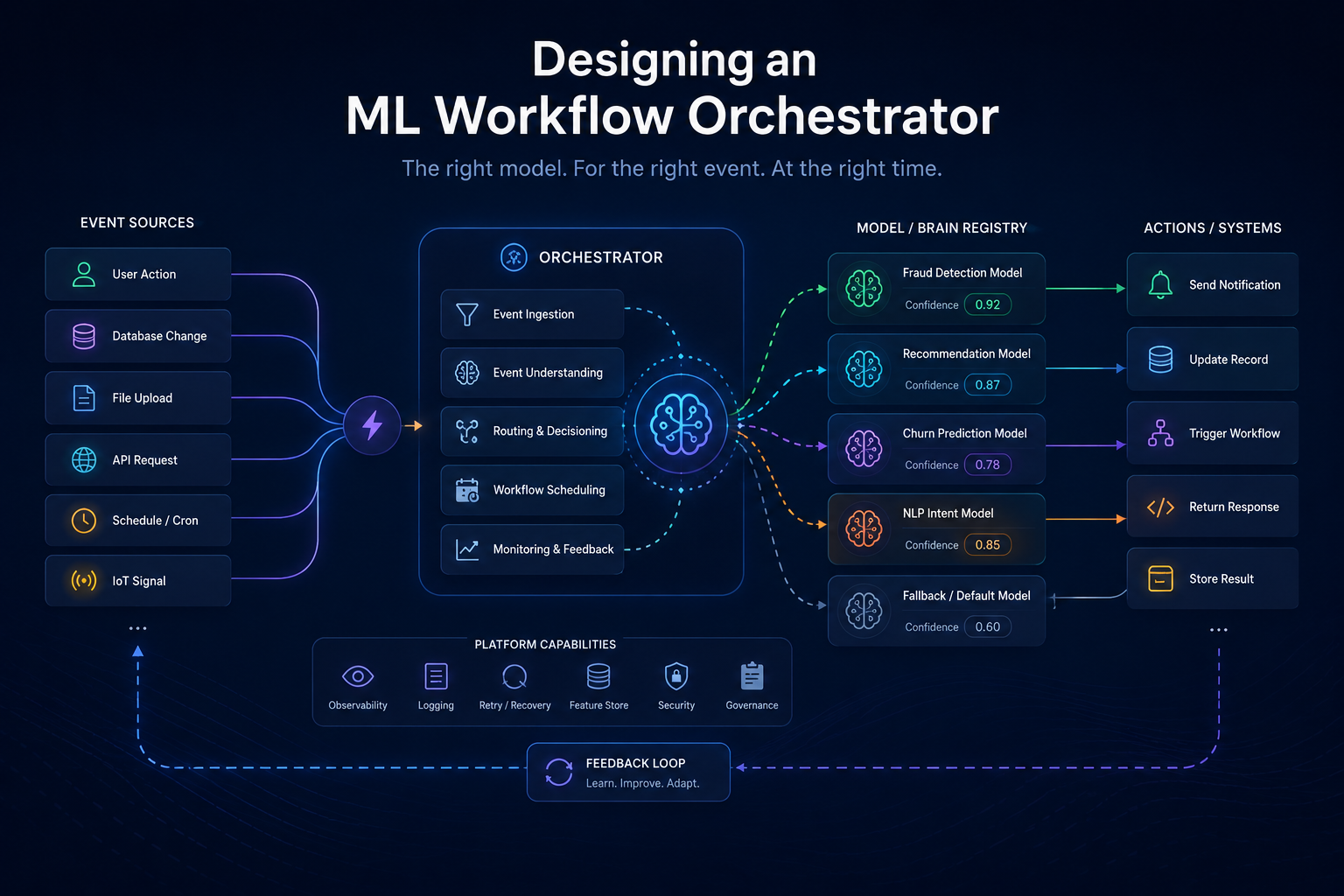
Not every problem needs the same brain. A fraud signal needs a fast binary classifier. A demand spike needs a time-series forecaster. A customer complaint needs an LLM reasoning carefully about context. The hard part isn't building those models — it's knowing which one to wake up, and when.
This post walks through a generic, real-world architecture for event-driven ML orchestration. We'll use a concrete example — a retail operations platform receiving thousands of mixed events per minute — to make the concepts stick. By the end, you'll have a blueprint for a system where events self-route to the right model, models operate independently, and the whole thing scales horizontally without a traffic cop in the middle.
Who this is for?
ML engineers standing up their second or third model in production, platform engineers asked to "productionize the ML stuff," and technical leaders designing a future-proof data platform. Familiarity with Kafka, REST APIs, and basic ML concepts assumed.
The Running Example: RetailPulse
Imagine RetailPulse, a mid-sized retailer that sells across its own website, mobile app, and third-party marketplaces. Every second, the platform generates events: page views, cart mutations, orders placed, inventory updates, refund requests, returns, support tickets, and raw clickstream data. Each event type carries a different signal — and demands a different response.
The ML team has built four models over the past two years, each solving a distinct problem:
-
Model A: Demand Forecaster Time-series model (Prophet + XGBoost ensemble) predicting 7-day SKU-level demand. Triggers on inventory restocking events and nightly batch signals.
-
Model B: Fraud Classifier LightGBM binary classifier detecting fraudulent order patterns in real-time. Triggered by every
order.placed event. SLA. -
Model C: Churn Predictor Gradient-boosted classifier scoring customers on -day churn probability. Runs asynchronously on
customer.inactiveandsupport.ticket.resolvedevents. -
Model D: AI Support Agent LLM-powered agentic workflow that reads ticket context, retrieves policy docs, and drafts resolution summaries. Triggered on escalated
support.ticket.escalatedevents.
The problem: all four models used to be called ad hoc — hardcoded in application services, triggered by cron jobs, or kicked off by analysts running notebooks. This was fine with one model. With four (and more coming), it became a tangle of custom scripts, inconsistent retry logic, and zero observability. The team needed an orchestration layer.
"The problem isn't building models. It's knowing which one to wake up — and proving it was the right choice." — Principal ML Engineer, RetailPulse
The Architecture at a Glance
The system is built around a single core insight: events are typed, and types determine workflow. Rather than having application code decide which model to call, we let a dedicated orchestration layer own that routing logic. This keeps model concerns separate from business logic and makes the system trivially extensible.
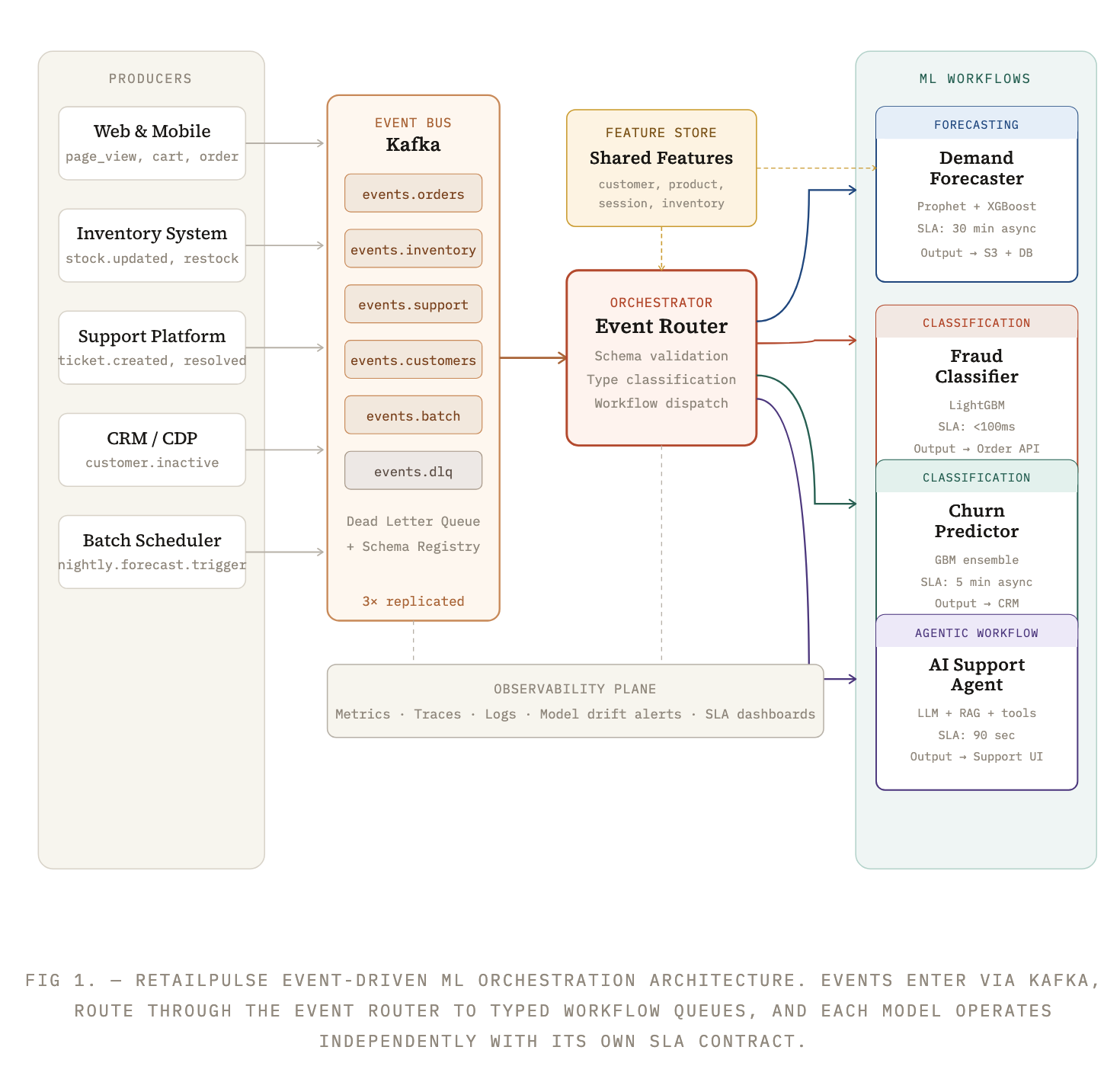
The Five Layers That Make It Work
Layer 1 — The Event Schema Contract
Every event in the system must conform to a canonical envelope schema. This is non-negotiable. Without a common schema, routing logic becomes a brittle pile of conditional checks. RetailPulse uses a Schema Registry. Every event must carry a type, source, version, and payload:
//canonical event envelope { "type": "record", "name": "RetailEvent", "fields": [ { "name": "event_id", "type": "string" }, { "name": "event_type", "type": "string" }, // e.g. "order.placed" { "name": "source", "type": "string" }, // e.g. "checkout-service" { "name": "version", "type": "string" }, // semver "1.2.0" { "name": "occurred_at","type": "long" }, // epoch ms { "name": "tenant_id", "type": "string" }, { "name": "payload", "type": "bytes" } // event-specific JSON ] }
The event_type field is the routing key. The schema registry enforces backward compatibility — adding fields is fine, removing them is a breaking change that requires a version bump and migration plan.
Layer 2 — The Event Router
The Event Router is a stateless service (typically a Kafka Streams application or a small Flink job) that does exactly one thing: read from the canonical input topics, validate the schema, and dispatch to model-specific queues. It contains a routing table — a mapping of event types to workflow targets:
# routing_table.yaml — single source of truth for event → workflow mapping routes: order.placed: workflow: fraud-classifier priority: high sla_ms: 100 queue: ml.fraud.input inventory.restock_requested: workflow: demand-forecaster priority: standard sla_ms: 1800000 # 30 minutes queue: ml.forecast.input customer.inactive: workflow: churn-predictor priority: low sla_ms: 300000 queue: ml.churn.input support.ticket.escalated: workflow: ai-support-agent priority: high sla_ms: 90000 queue: ml.agent.input nightly.forecast.trigger: workflow: demand-forecaster priority: batch sla_ms: 3600000 # 1 hour for full catalog queue: ml.forecast.batch
The routing table is data, not code. Stored in a config repo, deployed via CI/CD, versioned with git, and applied to the running router via a hot-reload API. No redeploy required to add a new route.
Layer 3 — Model-Specific Workflow Workers
Each model gets its own worker pool — a set of consumers that pull from the model's dedicated input queue. Workers are independently scalable via Kubernetes HPA, with replicas tuned to each model's throughput and latency characteristics. Crucially, each worker knows only about one model. It does not need to know about fraud detection to serve demand forecasting.
A worker follows a standard lifecycle:
| step | task |
|---|---|
| 01 | Consume event from model-specific Kafka topic |
| 02 | Deserialize payload and validate required feature fields |
| 03 | Fetch any missing features from the shared Feature Store (Redis + BigQuery) |
| 04 | Run inference (locally loaded model or gRPC call to model server) |
| 05 | Publish result to the output topic or call downstream API |
| 06 | Commit Kafka offset only after successful downstream write |
| 07 | On error: retry with exponential backoff, then route to DLQ |
Layer 4 — The Shared Feature Store
Multiple models share the same underlying features — customer lifetime value, product category, session recency, and so on. Without a feature store, each model recomputes these independently, creating drift and redundant work. RetailPulse uses a two-tier store: Redis for low-latency real-time features (sub-millisecond lookups, critical for the fraud classifier), and BigQuery feature tables for batch features refreshed hourly.
Features are computed by a separate streaming pipeline and pushed proactively. The models are consumers, never the source of truth for features.
Layer 5 — Observability and the Feedback Loop
This layer is often skipped in early designs and regretted later. Every inference in the system should emit a prediction event back to a dedicated output topic. This serves three purposes: downstream consumers can react to predictions, the observability pipeline captures every decision for audit and retraining, and alerting can fire when model outputs drift from historical norms
// Prediction event schema — emitted by every model worker after inference { "prediction_id": "pred_8a2f...", "model_id": "fraud-classifier-v2.3", "source_event_id":"evt_9c3a...", "entity_id": "order_10294", "output": { "label": "fraud", "confidence": 0.94, "decision": "hold" }, "latency_ms": 67, "feature_version":"2026-05-09T00:00:00Z", "predicted_at": 1715299200000 }
A Special Case: Agentic AI Workflows
The AI Support Agent (Model D) is architecturally different from the three ML models. It is not a simple inference call — it is a multi-step workflow that may call external tools, retrieve documents, and make several LLM calls before producing an output. This is what distinguishes an agentic workflow from a standard ML inference workflow.
An ML model takes features → returns a prediction in one call. An agentic workflow takes a trigger event → orchestrates multiple steps (retrieval, reasoning, tool use, validation) → produces an action. The event routing architecture handles both identically at the intake layer; the difference is entirely inside the workflow worker.
When a support.ticket.escalated event arrives, the AI Agent worker runs something like this:
async def handle_escalation(event: RetailEvent): ticket = parse_payload(event.payload) # Step 1: retrieve relevant policy documents docs = await vector_search( query=ticket.issue_summary, top_k=5, namespace="support-policies" ) # Step 2: fetch customer history from Feature Store customer = await feature_store.get( entity="customer", id=ticket.customer_id, features=["lifetime_value", "order_count", "prev_escalations"] ) # Step 3: reason and draft resolution with LLM draft = await llm.complete( system=AGENT_SYSTEM_PROMPT, user=build_prompt(ticket, docs, customer), tools=["issue_refund", "escalate_to_human", "send_voucher"] ) # Step 4: execute tool calls if model chose an action if draft.tool_calls: await execute_tools(draft.tool_calls) # Step 5: write output back to support platform await support_api.post_resolution(ticket.id, draft.summary) # Step 6: emit prediction event for observability await kafka.produce("ml.predictions", build_prediction_event(event, draft))
The event bus and router treat this identically to any other workflow — they don't know or care that the worker inside runs 5 LLM calls and two vector searches. This is the elegance of the architecture: the orchestration contract is uniform, and complexity is encapsulated inside the worker.
Scaling and Operational Concerns
Independent scaling per model
Because each model has its own Kafka consumer group and Kubernetes Deployment, scaling is independent. The fraud classifier scales to 40 replicas during peak checkout hours; the churn predictor idles at 2 replicas overnight. Autoscaling is driven by Kafka consumer lag — KEDA (Kubernetes Event-Driven Autoscaling) watches lag on each model's input topic and scales the corresponding deployment automatically.
Backpressure and the DLQ
Every model's input topic has a dedicated Dead Letter Queue. If a worker fails to process an event after three retries (with exponential backoff), the event is routed to the DLQ. A separate DLQ inspector service alerts on-call engineers, and failed events can be replayed after the root cause is fixed. The DLQ is a feature, not a failure. A system without one silently drops events or causes cascading retries.
Model versioning without downtime
New model versions are deployed as a second Deployment alongside the current one, both consuming from the same input topic using the same consumer group. Traffic is split using Kafka partition assignment. Once the new version is validated (via shadow mode comparison), old replicas are scaled to zero. This gives you canary deployment semantics without any application-layer traffic splitting logic.
Final Thoughts
The architecture described here — typed events, a stateless router driven by a config table, independent model workers, a shared feature store, and a uniform observability contract — is not novel. It draws directly from event-driven microservices patterns that have been production-proven for a decade. What is novel is applying these patterns deliberately to ML systems, where the temptation is always to solve orchestration inside the model code itself.
The separation of concerns is the point. Event producers don't know which model will process their events. The router doesn't know what models do internally. Models don't know about each other. Observability doesn't need to understand model internals to capture predictions. Each layer can evolve independently, and the system as a whole becomes more reliable precisely because no single component understands the whole picture.
The fraud classifier and the LLM support agent look nothing alike on the inside. But from the perspective of the orchestration system, they are both workers that consume from a queue, do something with the event, and emit a result. That uniformity is what lets the system scale — in throughput, in the number of models, and in the size of the team that operates it.
If you're starting from scratch: get the schema contract right first. Everything else — routing, workers, feature stores, observability — can be evolved incrementally. A bad schema contract requires a painful migration later. Get it right on day one and the rest follows naturally.